A Structured Way to Choose the Right AWS Compute Service
Many teams choose AWS compute services based on habit rather than reasoning. This article introduces a structured decision model that maps workloads to the right compute option, helping engineers make consistent, evidence-based choices instead of preference-driven ones.

Introduction
AWS offers one of the most extensive compute portfolios in the industry. Each service exists for a valid reason, yet the overlap between them is substantial.
As a result, engineering teams often spend more time deciding where to run code than how to design it.
The real challenge isn’t too many options. It’s a lack of a consistent framework for choosing between them.
Decisions are frequently driven by habit or perceived cost instead of measurable constraints such as execution duration, scaling behaviour, or isolation needs. This creates what can be called decision debt — architectural choices made without a repeatable rationale. Over time, that debt manifests as operational friction, cost anomalies, and migration complexity.
A Structured Way to Decide
To bring structure to this complexity, I built a decision model that maps workloads to the smallest viable set of AWS compute services. The following decision tree visualises that reasoning process, starting with location and pattern, and converging on the most appropriate execution model.
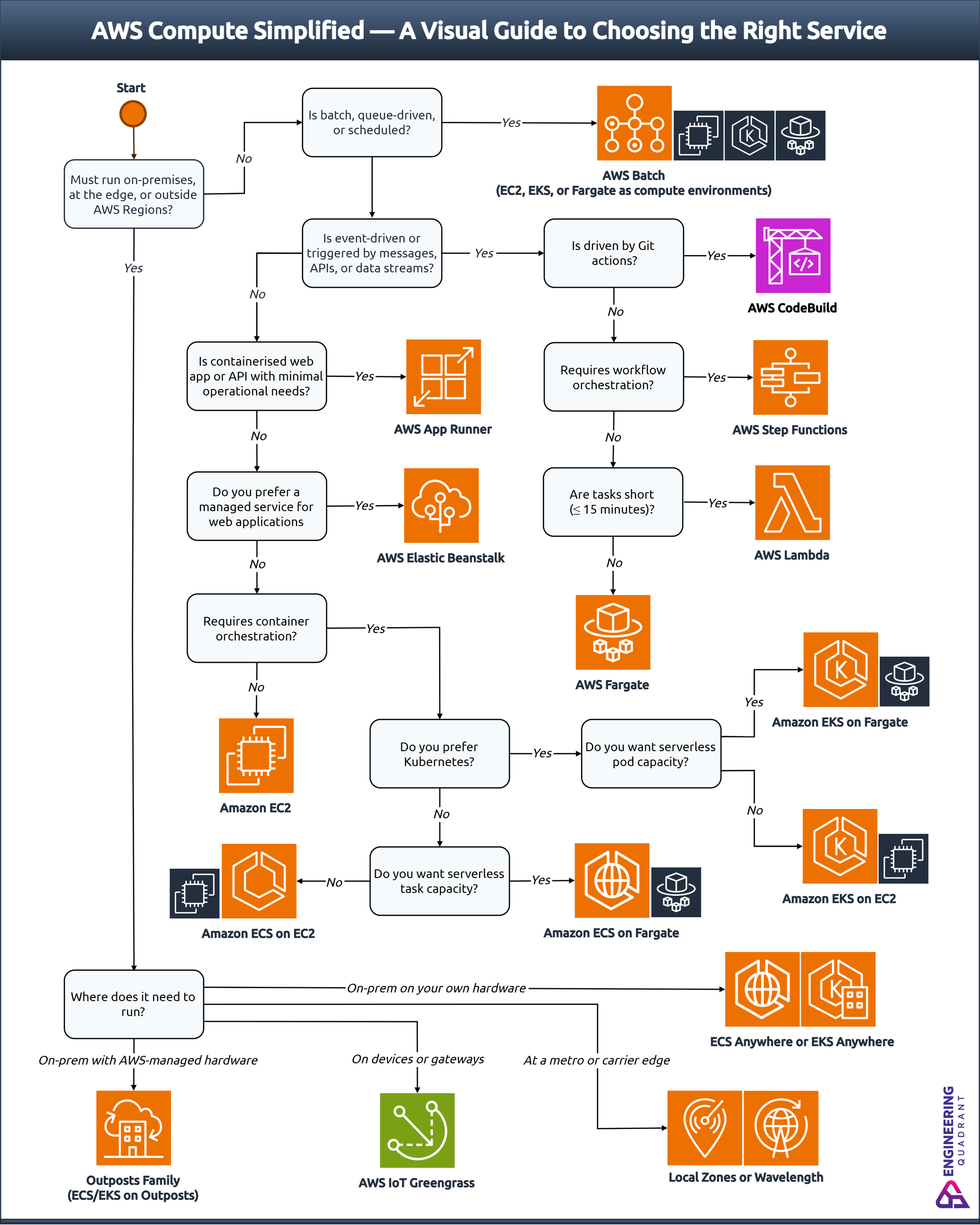
From an architectural standpoint, AWS compute services represent points along three axes of choice:
- Operational control – from fully managed (serverless) to fully administered (virtual machines).
- Workload duration and concurrency – from bursty and event-driven to steady and long-running.
- Application abstraction – from code-level (functions) to infrastructure-level (instances).
The objective is not to recommend a single service, but to establish a repeatable reasoning process that can be applied to any new workload. By reasoning from constraints rather than preference, teams can narrow a dozen overlapping services down to one or two valid options.
How AWS Compute Options Differ
Choosing the right compute service means understanding how AWS actually runs workloads.
Every compute decision can be framed around three dimensions: workload pattern, operational control, and runtime requirements.
1. Workload pattern
The most important discriminator is how the workload behaves over time.
| Level of control | Description | Primary services |
|---|---|---|
| Fully managed | AWS handles capacity provisioning, patching, scaling, and availability. Developers focus only on code or container images. | Lambda, App Runner, Fargate |
| Managed orchestration | AWS manages orchestration, but customers manage container images, task definitions, and runtime tuning. | ECS, EKS |
| Self-managed | Full administrative control over instances, networking, OS, and deployment tooling. | EC2, Outposts |
Correctly classifying a workload pattern dictates execution duration, scaling triggers, and pricing model.
Tip: Trying to force a steady-state workload into an event-driven platform will inflate costs and degrade observability.
2. Operational control
Each AWS compute service exists on a continuum between fully managed and fully administered. Where does your team want to sit on the spectrum between no infrastructure management and full administrative control?
| Level of control | Description | Primary services |
|---|---|---|
| Fully managed | AWS handles capacity provisioning, patching, scaling, and availability. Developers focus only on code or container images. | Lambda, App Runner, Fargate |
| Managed orchestration | AWS manages orchestration, but customers manage container images, task definitions, and runtime tuning. | ECS, EKS |
| Self-managed | Full administrative control over instances, networking, OS, and deployment tooling. | EC2, Outposts |
Control correlates with responsibility. Many teams unintentionally assume operational ownership without realising the lifecycle cost that follows.
Tip: The more control you assume, the more you inherit. Consider the increased effort for patching, scaling, compliance, and cost management.
3. Runtime requirements
Certain workloads have constraints that immediately rule out specific services. Before evaluating features, confirm that runtime constraints don’t already exclude certain services.
| Constraint | Implication | Suitable services |
|---|---|---|
| Execution time > 15 minutes | Exceeds Lambda’s limit; requires container or VM-based service. | Fargate, ECS, EKS, EC2 |
| Requires GPU, large RAM, or custom kernel | Needs underlying instance selection. | EC2, ECS on EC2, EKS on EC2 |
| Strict networking or VPC configuration | Demands full network control and integration with enterprise routing. | ECS, EKS, EC2 |
| Cold-start sensitivity | Low-latency APIs or near-real-time workloads may not tolerate cold starts. | ECS, EKS, EC2, or Lambda with Provisioned Concurrency |
| Windows or specialised licensing | Requires OS-level access. | EC2, ECS/EKS on EC2 |
Runtime constraints are often overlooked in early design discussions, yet they have the greatest influence on feasibility. Identifying them first prevents later redesign or cost escalations.
Tip: Constraints define feasibility. Features define optimisation.
Together, these three dimensions: pattern, control, and runtime, form the analytical base of the AWS compute decision tree.
Once defined, they narrow the choice from a dozen overlapping services to just one or two logical options.
Conclusion
Selecting an AWS compute service shouldn’t rely on habit or assumption.
When decisions start with constraints such as where the workload runs, how it behaves, and what it requires, the viable options emerge naturally.
The AWS compute decision tree turns architectural judgement into a repeatable process. It replaces preference-led debate with evidence-based reasoning. The objective is aligning workloads with the right level of control, performance, and scalability.
Architectural maturity in the cloud isn’t about picking one perfect AWS service, but about applying a consistent, logical process to compute decisions.



